Extracting data from OSM file with Dynamo and Python
While there are some great packages available, like Elk or DynaMaps, to do the task – sometimes we need some data that is not possible to obtain with them. In this post I am gonna show a method to extract necessary data using Python.
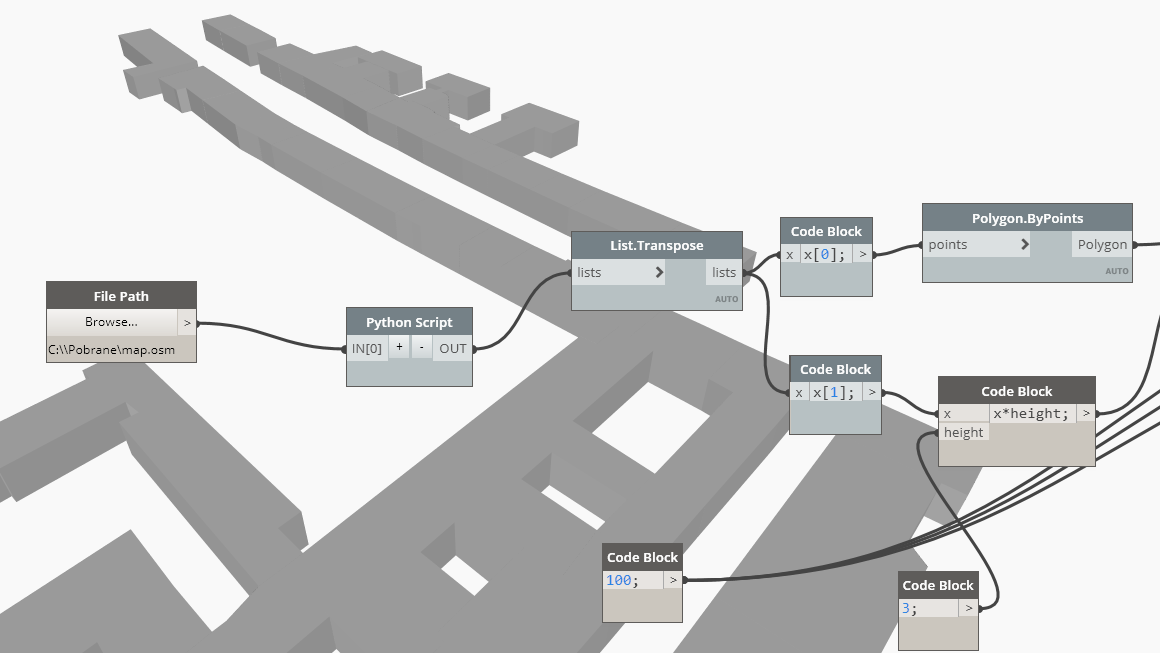
For parsing a XML file I am gonna use a standard Python library called xml.etree.ElementTree. In the example I will extract building boundaries and their floor number. OSM files do sometimes contain precise height data for buildings, however I have found that floor count is found more often.
Typical OSM section that describes a building looks like so:
<way id="28095147" visible="true" version="4" changeset="49823984" timestamp="2017-06-25T22:16:38Z" user="kocio" uid="52087">
<nd ref="308595334"/>
<nd ref="308595359"/>
<nd ref="308595338"/>
<nd ref="308595345"/>
<nd ref="4936195428"/>
<nd ref="308595331"/>
<nd ref="308595334"/>
<tag k="addr:city" v="Warszawa"/>
<tag k="addr:housenumber" v="8"/>
<tag k="addr:postcode" v="00-020"/>
<tag k="addr:street" v="Chmielna"/>
<tag k="building" v="yes"/>
<tag k="building:levels" v="3"/>
</way>
Sections for objects, such as buildings, are enclosed within a <way> tag. Inside the section we can find <tag> elements containing two attributes “k” and “v” (like “key” and “value”). If an object is a building than it contains a <tag> with a “k” attribute that equals “building”. Knowing that we can search the XML file and find all the buildings in it.
Another important element of the building section is a <nd> element. It is going to contain only one attribute – a reference to a node section, found elsewhere in the file. These nodes are corner points of the building’s boundary.
So, in the same XML file we can find a <node> section with a proper “id” value (as referenced in the building section):
<node id="308595334" visible="true" version="2" changeset="51689947" timestamp="2017-09-03T10:59:36Z" user="tkedt" uid="2284681" lat="52.2331940" lon="21.0179163"/>
Important attributes here are “lat” and “lon”, describing geographical coordinates of the point. To make them useful for Dynamo we have to convert them to x,y coordinates. I am not going to elaborate on that part, but a necessary function is included in the final code at the bottom of the post.
The last element of the building section, that is of importance to us, is a <tag> element with “k” attribute “building:levels”. Obviously it contains information about the number of levels – stored in the “v” attribute.
So, knowing all the above, we can start with scripting. As we are going to need node data while parsing buildings, first we will create a node list (actually a dictionary). This way we will be able to locate specific node coordinates easily.
root = xml.parse(file_path).getroot()
children = root.getchildren()
nodes = {}
for c in children:
if c.tag == "node":
nodes[c.attrib["id"]] = [c.attrib["lat"], c.attrib["lon"]]
The above code is creating a “nodes” dictionary, where node “id” is a dictionary key. Value contains a list of geographical coordinates.
Around this part of the function (in the complete code) I am also parsing a <bounds> tag. Again it is connected to coordinate conversion and again I am not going to describe it in the detail.
Finally we can get to the proper part of the code, which extracts building data:
output = []
for c in children:
if c.tag == "way":
outline_nodes = []
is_building = False
levels = 0
for t in c:
if t.tag == "tag":
if t.attrib["k"] == "building":
is_building = True
if t.attrib["k"] == "building:levels":
levels = int(t.attrib["v"])
if t.tag == "nd":
outline_nodes.append(t.attrib["ref"])
if is_building:
outline = []
for on in outline_nodes:
lat = float(nodes[on][0])
lon = float(nodes[on][1])
xy = ll_to_xy(lat,lon)
p = Point.ByCoordinates(xy[0],xy[1])
outline.append(p)
output.append([outline,levels])
There are two steps in this loop. Firstly, for each <way> tag we check if it describes a building (attribute “k” that equals “building” can be found). We also look here for elements describing node references and floor count.
If the section proves to be a building, in the second part, a data structure describing the building is created. It is a list containing boundary and floor number data. The list is then appended to the output variable.
Below the entire Python code is presented. It takes an OSM file path as an input and outputs a list of buildings, containing extracted data for each one of them.